Os estudos iniciais sobre IA (Inteligência Artificial), que apresento nos tópicos anteriores se dedicam a estudar os algorítmos estatísticos (KNN,SVM e Naive Bayes) para os dados numéricos e análises estatísticas para os dados textuais.
Para este tópico, redes neurais, o estudo se baseia nas redes neurais artificiais que, no meu entender, estão mais próximas do que vem se chamando, não corretamente, de inteligência artificial. A simulação dessas redes às redes biológicas torna o estudo bastante interessante, daí eu achar que vale uma introdução mais detalhada do assunto, principalmente para quem não o conhece bem, antes de executar os algorítmos que resolvi estudar.
Sendo assim, vamos ver alguns conceitos e uma noção mais detalhada do que é processado pelos algorítmos, antes de executá-los.
Comecemos conceituando como rede neural biológica uma série de neurônios interconectados,
ligando seus terminais axônicos, via sinapse, à dendritos de outros neurônios. Por
analogia, vamos conceituar uma rede neural artificial similar a rede neural biológica,
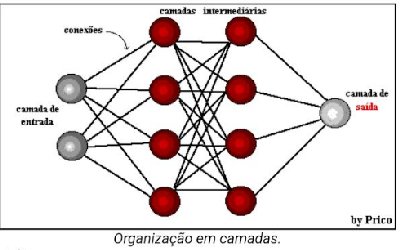
composta por camada de nós (neurônios artificiais), com a seguinte estrutura:
a) camada de entrada
b) uma ou mais camadas intermediárias, chamadas de ocultas
c) camada de saída
Os nós são conectados, possuindo peso (valor de importância da variável) e valor limite
a cada um. O dado de cada nó só é passado para a camada seguinte se o valor de saída
superar o limite estipulado. Os pesos são atribuídos à camada de entrada, valorizando
adequadamente os seus nós. A camada de saída é gerada por uma função apropriada. A saída de cada nó,
se exceder o valor estipulado, se torna a entrada do próximo nó. Essa saída é definida
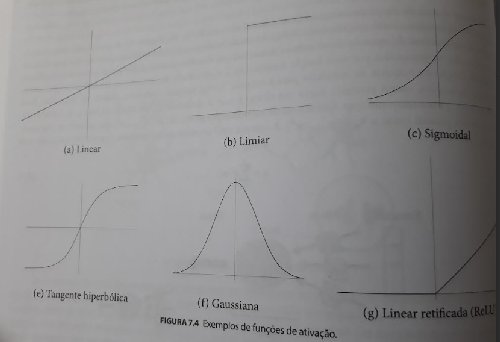
pela aplicação de uma função de ativação. As funções mais usuais são: linear, limiar,
sigmoidal, tangente hiperbólica, gaussiana e linear retificada(ReLU), conforme mostradas
abaixo:
A figura abaixo mostra a forma de uma rede neural artificial.
O processo de passagem dos dados de uma camada para a próxima é conhecido como
'feedforward', ou seja, alimentação para a frente.
Uma vez construído o modelo de rede neural artificial é necessário treinar o modelo para avaliar a sua precisão. Para isso, é comum usarmos uma função de perda (erro). Ao minimizarmos a perda, aumentamos a precisão do modelo. Normalmente, as redes neurais são 'feedforward' (entrada-> saída), mas o modelo pode ser treinado com retropropagação (saída-> entrada).
Os tipos mais comuns de redes neurais artificiais são:
Perception
Comporta o modelo básico (camada de entrada, uma ou mais ocultas e uma de saída).
Convolucionais
São, normalmente, do tipo perception, utilizadas para reconhecimento de padrões (imagens,
por exemplo).
Recorrentes
São caracterizadas por ciclos de retroalimentação, muito utilizada em previsões.
As redes neurais aprendem e se adaptam aos padrões das variáveis de entrada, o que difere do processamento convencional que gera resultados sem fazer adaptações, resultantes do treinamento. Quanto maior for a qualidade dos dados e sua quantidade, menor é o erro de aplicação das redes neurais na geração dos resultados.
Pode-se resumir os os passos de processamento da rede neural artificial como:
Treinamento
Para um bom conhecimento das variáveis de entrada
Validação
Para se fazer um ajustamento dos dados
Teste
Para verificar o erro e avaliar a precisão
À medida que a rede neural aprende, seus pesos e vieses são ajustados. Pode-se controlar a velocidade de aprendizado e a duração do treinamento. As redes neurais que usam retropropagação são importantes no aprendizado, pois isto ajuda a ajustar os pesos e os vieses para reduzir o erro.
A função de ativação de um rede neural decide se um nó(neurônio) deve ser ativado, baseado na soma ponderada de suas entradas e o valor limite(viéis).
O aprendizado de uma rede neural pode se realizar como:
Supervisionado
Quando é informado à rede o resultado desejado para um padrão de entrada
Não supervisionado
Quando não existe a informação deste resultado
Reforço
Quando há uma avaliação externa dos resultados fornecidos pela rede neural
No treinamento supervisionado, que é bastante usado, o esquema de treinamento é :
iniciar com pesos aleatórios e fazer processamentos repetidos até que o erro
seja menor que o proposto. Enquanto não for, ir atualizando o pesos e verificando
os limites.
Agora, com esses conceitos em mente, vamos entender o que faz cada algorítmo apresentado,
programados na linguagem PHP:
ALGORÍTMO 1
(dados numéricos)
São lidas as quatro notas e calculada a sua média aritmética. Esses dados são normalizados entre 0 e 1, dividindo-se todos esses valores por 900, que foi considerada a nota máxima.
Criam-se duas camadas ocultas na rede neural artificial, com taxa de aprendizado e
de duração de 10000 ciclos. Foram criados pesos aleatórios, que serão utilizados nos
cálculos entre as camadas de
entrada e as ocultas, assim como das camadas ocultas para a de saída.
Foi feito um treinamento com os 10000 ciclos, na forma 'feedforward' das
camadas de entrada para as ocultas, assim como das ocultas para a de saída,
onde foi usada a função sigmóide.
Em cada ciclo, foram verificados os erros e feita uma retropropagação com a
derivada da função sigmóide para atualização dos pesos.
Após o modelo estar treinado, recebeu-se os dados de entrada (as quatro notas
para a previsão).
Com os dados de entrada normalizados e respectivos pesos ajustados no modelo,
foram preenchidas as camadas e, baseado nesses cálculos, foi feita a previsão
da nota média para os novos valores que deram entrada.
(dados categóricos)
O processamento é o mesmo dos dados numéricos, diferindo apenas nos dados
da camada de entrada, que são as categorias: idade, sexo, estado civil,
cor/raça, nacionalidade e escola-origem.
A normalização desses dados, para os valores entre 0 e 1, é feita dividindo-se
os valores das categorias por valores máximos 20, 1, 4, 6, 4 e 3, respectivamente.
ALGORÍTMO 2
(dados numéricos)
São lidas as notas (CN,CH,LC,MT) e calculada a média aritmética
Para o treinamento são calculadas as distâncias euclidianas entre os valores que deram entrada,
classificadas por ordem ascendente e, finalmente, comparadas essas distâncias com as
médias aritméticas de entrada.
Ao final das comparações, chega-se a previsão da média referente aos novos dados de entrada.
(dados categóricos)
São lidas as categorias de entrada: idade, sexo, estado civil, cor/raça, nacionalidade,
e escola-origem, sendo geradas as médias aritméticas das notas CN,CH,LC e MT.
Para o treinamento os pesos são calculados aleatóriamente para as seis categorias,
com uma taxa de aprendizagem de 0,001 numa duração de 1000 ciclos.
Com base nos pesos calculados e o valor das categorias são calculadas as novas médias. Em seguida,
os erros (desvio da média) são calculados e os pesos atualizados, até uma
aproximação idealizada, quando é gerada a média prevista para os novos dados que deram
entrada.
ALGORÍTMO 3
(dados numéricos)
São lidas as notas das provas CN,CH,LC e MT e média aritmética é categorizada em
quatro tipos:
menor que 250, entre 250 e 500, entre 500 e 750 e maior que 750
Para o treinamento são calculadas as distâncias euclidianas entre as notas,
classificadas ascendentemente e comparadas com as categorias de classificação das
médias, guardando-se esses valores.
Os novos dados de entrada são comparados a esses valores gerando a categoria mais
próxima como previsão.
(dados categóricos)
É o mesmo procedimento dos dados numéricos só que, neste caso, são usados os
valores das categorias: idade, sexo, estado civil, cor/raça, nacionalidade e
escolaorigem, ao invés de se usar as notas das provas.
ALGORÍTMO 4
(dados numéricos)
São lidas as notas das provas e calculada as médias aritméticas. Se a média
calculada superar a média informada é dado ao valor 1, caso contrário é dado um
valor zero. Para o treinamento, ficam estabelecidos os valores: 4 nós na camada de entrada,
5 nas camadas ocultas, taxa de aprendizagem 0,1 e uma duração de 10000 ciclos.
A geração de pesos aleatórios é estabelecida no intervalo de -1 a 1.
Baseado nesses parametros é feito o treinamento no processo 'feedforward', possibilitando
uma retroprpagação com as saídas geradas. A cada cálculo do erro (desvio), os pesos
são atualizados e recalculado os pesos viéis.
Uma vez o modelo treinado, ele é testado com as novas entradas das notas das provas,
prevendo se resultará numa aprovação (valor > 0,5) ou numa reprovação (valor < 0,5).
(dados categóricos)
É o mesmo procedimento só que foram usados os valores das categorias: idade, sexo,
estado civil, cor/raça, nacionalidade e escola-origem.
Nesse caso, ficam estabelecidos os valores para treinamento: 6 nós na camada de entrada,
5 nas camadas ocultas, taxa de aprendizado igual a 0,1 e uma duração 10000 ciclos.
No restante, o processo é o mesmo usado para os dados numéricos, até a geração do
valor de previsão (aprovado ou reprovado).
ALGORÍTMO 5
(dados numéricos e categóricos)
Neste caso, as notas das provas são categorizadas como:
categoria 0 -> notas menores que 201
categoria 1 -> notas entre 201 e 400
categoria 2 -> notas entre 401 e 600
categoria 3 -> notas maiores que 600
É calculada, também, as médias aritméticas das notas das provas. Também são
lidos os valores associados às categorias: idade, sexo, estado civil, cor/raça,
nacionalidade e escola-origem
Com isto, tendo os dados categorizados é gravado um arquivo interno, que será
usado no treinamento, contendo apenas as variáveis categorizadas(só nomes, sem
números)
Esse arquivo é lido, gerando-se valores próprios de classificação, conforme suas
ocorrências.
A seguir, é feita a inicialização dos pesos aleatórios entre 0 e 1. Com base
nesses pesos é feito o treinamento com taxa de aprendizado igual a 0,01 numa
duração de 1000 ciclos.
É verificado o erro e, com base nisto, os pesos são atualizados no ciclo.
Com o modelo treinado é verificada a nova entrada de valores, que sofre o mesmo
processo de categorização para a previsão da média.